abstract
- 论文地址:Deep Compression: Compressing Deep Neural Networks with Pruning, Trained Quantization and Huffman Coding
- 论文主要针对神经网络计算量和占内存都较大的问题,提出对网络进行压缩的方法,主要有3个步骤:模型裁剪、量化以及Huffman编码。前两个步骤使用之后,对网络重新训练,对剩余的连接和量化的中心进行finetune。
- 效果:裁剪将连接的个数减少了9~13倍,量化将每个连接的表示由32bit减少到5bit。最终速度可以提升3~4倍,能耗减少了3~7倍。
introduction
- 模型压缩的整理流程图如下所示
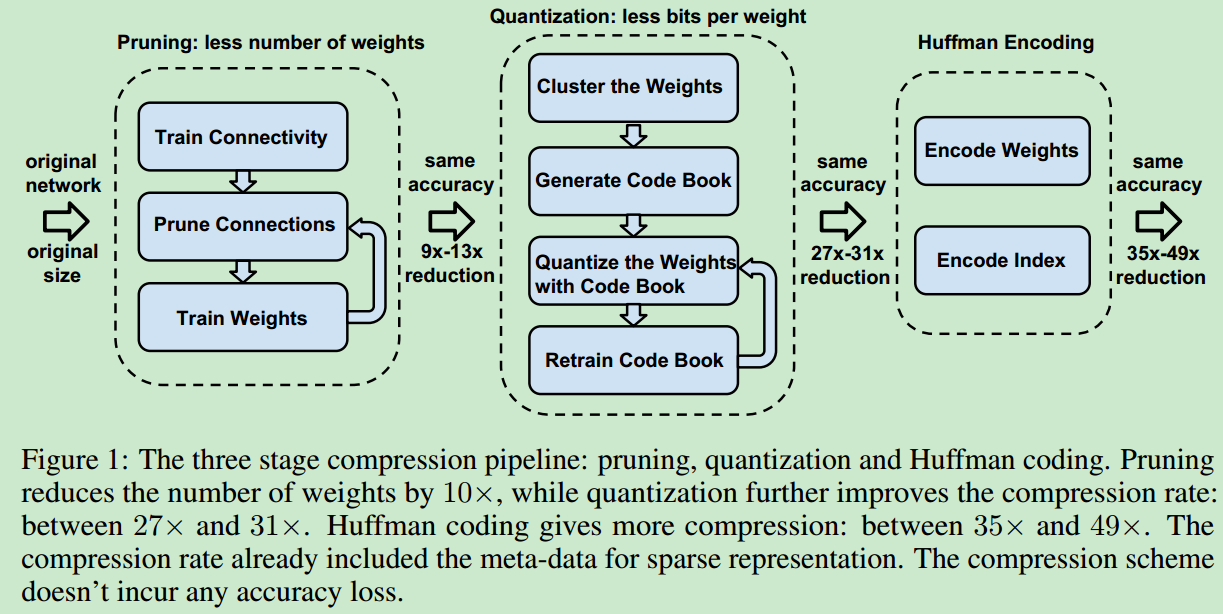
network pruning
- 对于权重很小的连接进行去除(小于特定阈值),如下图。
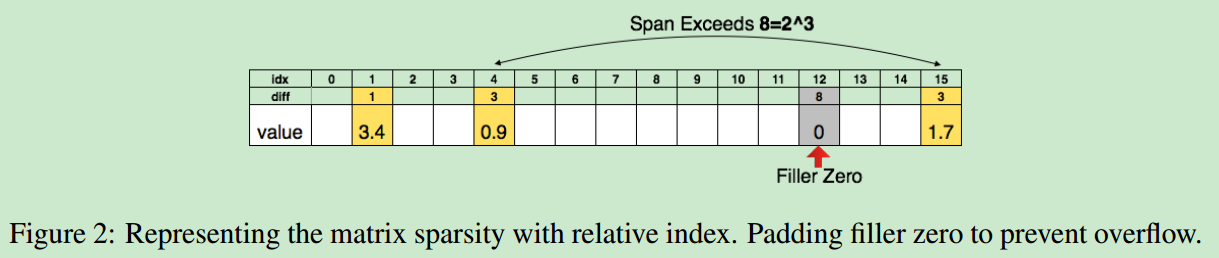
为了进一步压缩模型,使用有效权重index的相对位置去记录他们的信息而非使用index的绝对位置,因此如果2个有效权重之间的index距离大于8,则将他们之间填充一个0。
trained quantization and weight sharing
- 网络权值共享和量化的方式如下图所示:
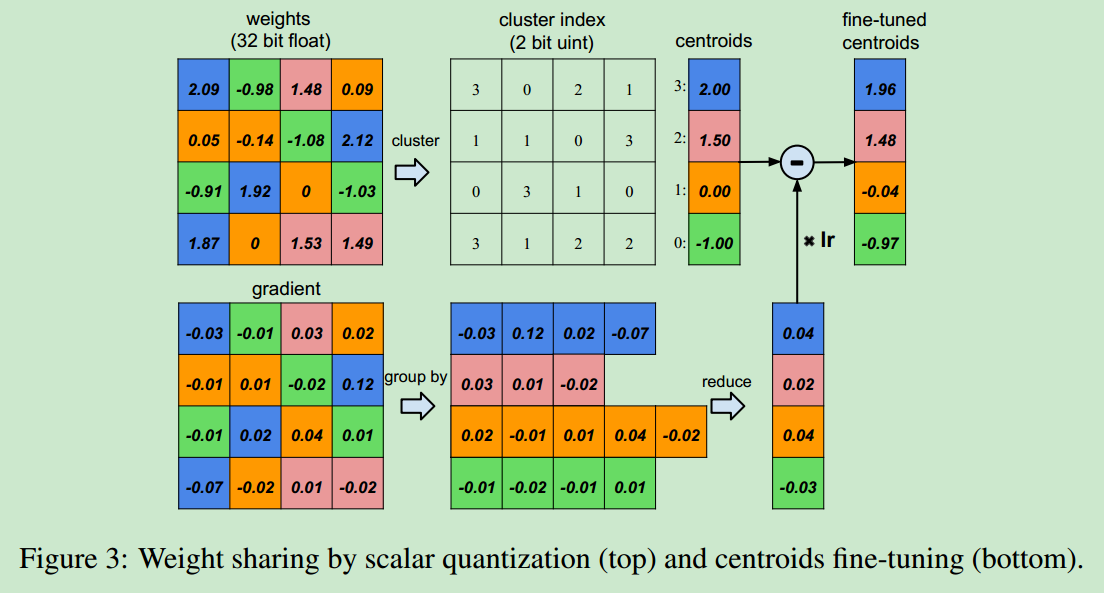
- 考虑训练得到的一个网络,其包含4个输入与4个输出,因此可以得到一个4X4的权重矩阵,首先对其进行聚类,然后取每个类别的均值作为这个类别的权重。这样可以大大减小有效权值的个数。
- 在聚类之后,需要对压缩后的模型进行finetune,即在反向传播时,使用聚类之前那些位置对应的权值的均值作为压缩后模型的梯度,之后再使用梯度下降法进行权重更新即可。
- 在聚类的过程中,使用kmeans进行聚类,kmeans的结果对初始点的选择比较敏感,因此作者用基于密度的初始化、线性初始化以及随机初始化三种方法进行聚类,线性初始化的方法能够比较好地保留那些较大的信息,后面的实验也验证了使用线性初始化的方法得到的压缩模型的精度最高。
Huffman coding
- 使用Huffman编码,针对非均匀分布的值,可以减少20%~30%的网络存储空间。
experiment
- 在mnist(lenet)、imagenet(vgg-16)上做了测试,验证了模型压缩方法在没有精度损失的情况下,参数量大大减少,模型速度有较大提升。
discussion
- 单独使用模型剪枝或者量化的时候,模型精度随压缩比的提升而下降的比较明显,而他们共同作用时,能够在保证较大的压缩比的情况下,仍然使得模型有很高的精度。
- 通过对kmeans的初始化方法进行实验,验证了线性初始化能够得到最优的模型性能。
- 目前blas库不支持relative indexing,因此没有在量化模型上面做实验,主要针对模型裁剪做了实验,在多个平台是,速度可以提升2~9倍,能够也减少了3~7倍。
- 将权重矩阵由dense变为sparse,需要记录sparse matrix中非零数值的下标,这部分额外的存储开销经过实验验证,发现只占整个网络很小的一部分。
future work
- 量化这一步骤由于没有支持indirect lookup和relative index的库与硬件,目前还没有做实验,需要有支持定制化的GPU kernel软件来支持这样的操作,定制化ASIC架构的硬件方案也支持定制化量化位宽的操作。
conclusion
- 论文主要就是在从3个角度(裁剪、量化与Huffman 编码)对神经网络模型进行压缩,在模型精度不受影响的情况下尽可能减小的大小与计算能耗。